漫谈 CloudDrive2 的文件缓冲机制
坑边闲话:本文最初发布于哔哩哔哩专栏。这篇文章属于临时起意,后来审阅文章时发现技术细节上有严重问题,该部分描述目前已经被修复,一切内容以本博客为准。
此前我在视频 BV1iAPgexEi6 里提到可以使用 OpenList/CloudDrive/Rclone/Raidirve 这种网盘工具把网络盘挂载到本地,实现云盘本地化使用。现在我感觉有点过于理想了。
想说的东西很多,今天这篇专栏就当作打草稿,读者且来批判性观看。
1. CloudDrive2 的缓存模型·
任何读写模型都有流控机制,哪怕是本地的 PCIe NVMe 硬盘,也会借助 PCIe 协议的 Credit-Based Flow Control 做流控。当然,这不同于 TCP 的滑动窗口,PCIe 流控协议更倾向于低延迟,目标是防止缓冲区溢出。
所以按照这个观点来看,在我们的 PC 通过 CloudDrive2 往网盘写入数据的过程中,CloudDrive2 也需要有一个缓存、流控协议用来处理本地的写入请求,防止本地的文件浏览器或者 rsync 这种 sender 把 buffer 写爆。
CloudDrive2 可以设置缓存目录:
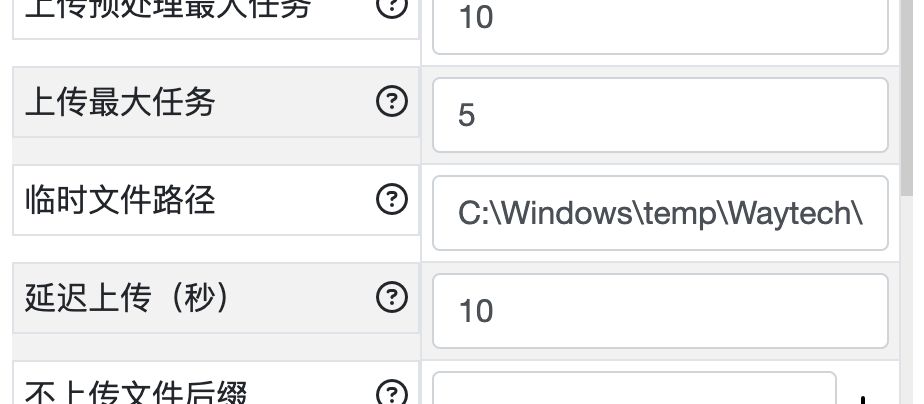
我一般把它放到 C:\Windwos\temp 目录下,这是标准的 Windows 缓存目录。
1.1 FreeFileSync 进行写入·
我们可以借助文件浏览器、FreeFileSync、rsync 等软件将本地文件同步到网盘,这非常方便。
以 FreeFileSync 为例。FreeFileSync 往云端挂载路径的写入请求,被 CloudDrive2 缓存下来,CloudDrive2 的缓存写入成功之后,CloudDrive2 会立即给 FreeFileSync 反馈写入成功。然而,实际上云存储里并没有写入数据,所以这当然属于缓存一致性问题。只不过我们知道,在网络良好的情况下,缓存一致性终究会得到解决,但是一定要注意,一定要人工确认 CloudDrive2 后台的工作队列清空之后再删除源文件、清理本地的备份,否则一旦 CloudDrive2 缓存丢失就欲哭无泪了,届时你将面对:
- 源文件已经被自己删除;
- CloudDrive2 缓存目录丢失,无法继续往云盘同步数据;
- 云盘没有接收到文件,为空。
然而可怕的是,我发现 CloudDrive2 没有做缓存控制算法,如果传输大量文件,CloudDrive2 会尽可能地去填满缓存目录,直到把系统盘 C:\ 写爆,此后会发生什么,我只能说画面太美,不敢想象。
可能 CloudDrive2 比较自信,假设
- 用户上传的文件基本都是可以秒传;
- 或者用户的 CloudDrive2 缓冲区足够大;
- 抑或是用户的传输量并不大。
因此基于上述假设,CloudDrive2 认为只要哈希算得够快、网速足够理想,缓存就可以及时清理。然而,对于我自己压缩的备份文件,秒传是不可能的,于是就产生了缓冲区写爆的问题。
2. 怎么解决问题·
2.1 调整工作队列·
通过调节 CloudDrive2 的哈希计算队列 (preprocessing)、发送队列 (transfering) 的大小可以控制 CloudDrive2 的工作强度。我们可以在后台把 transfer 队列容量设置得尽可能小,preprocessing 也尽可能小,这样发送队列就会小,不容易被云盘封控。在这样的情况下,因为封控而卡住上传队列进而导致缓冲区写爆的问题可以基本解决。
只有一种情况我不知道会不会出问题,那就是单一文件体积过大,大过了缓冲区容量。这时候是否会回退到无缓冲机制?我就不知道了,毕竟 CloudDrive2 是不开源的软件。
文件级别的缓存就是这么离谱,因为文件的体积是不可预料的,只有真正的块级别缓存才好使。粒度过粗总是面临问题。
2.2 优化存储算法·
下面提几个我觉得有道理的方案。
首先是本地的 CloudDrive2,何必使用文件级别的缓存呢?直接把文件缓存优化为文件指针构成的队列不就行了?其实也没有这么简单
CloudDrive2 保留真实缓存的目的很简单,那就是尽可能保证数据一致性。因为发送端有可能重复提交修改过的文件,这时候保留文件指针就必须加文件锁,加锁在文件同步中是大忌讳!
比如对于文件 F,我们一分钟一个版本,F1 F2 F3 …
上传的时候就需要保证云端也能依次接收这些版本。如果上锁,那么在传输 F1 的过程中,就不能编辑 F,导致生产线被阻塞。因此拷贝 F1 到缓存是一个很合适的方案。
大部分系统是不支持文件快照的,如果可以对文件拍快照,那么就可以无锁了。
3. 两难的局面·
所以两难的局面出现了。
第一,拷贝机制需要进行对发送者进行干预,比如通过不给 sender 发送提交成功的信号进而阻塞发送队列。这是一个好方法,可以保护缓冲区不被写爆,这等同于对数据加锁。但是发送者迟迟不能提交也会阻塞进程。当然,这对备份场景是毫无影响,这也是我认为比较理想的局面。但是难以应付非备份场景,频繁提交。
第二,用文件指针替代缓存。这对与备份也是很合适的,甚至比第一种要好,它可以优化缓存设备的寿命。不得不感叹备份真是太好伺候了。然而在真实场景下这种机制就是灾难,同步上锁等待网络传输,想想就难受!
4. 期待·
据我早期推测,CloudDrive2 可能设计了两级流水:
- 第一级:秒传哈希计算,sender 发过来的所有东西都先在内存里计算一次哈希(毕竟哈希计算很快,数百 MB/s),不入本地缓存,然后「应秒尽秒」,期待文件不要走到接下来的流水线上;
- 第二级:若第一级哈希计算没有命中云端数据,就会写入本地缓存,等待上传。流水一直走,直到缓存写爆,接下来发生什么就不得而知了。
当然,我没有做极限测试,因为任由服务器写爆 C:\ 是很危险的,有可能无法开机,所以我只观测到 512GB 的 C 盘仅剩 40GB 到 80GB 可用空间就手动停了。
后来发现,如果不使用 CloudDrive2 的备份功能而直接往 CloudDrive2 挂载路径里写数据,无论如何 CloudDrive2 都会直接把数据写到缓冲区。缓冲区空间有限,而且 fuse/winfsp 声称的可用空间(即云盘可用空间)一般远远大于缓冲区空间。因此,操作系统在写入数据时观测到可用空间足够大,于是就直接写入了。然而,一旦触碰到缓冲区的空间上限,就会发生不可预料的结果。
这相当于一个假的 2TB 硬盘,它说自己有 2TB 可用容量,但实际上只有 128GB,当你往里面写入 1TB 数据时,结果自然是数据火葬场。所以问题就出在这个“空间错觉”:
- 你以为写的是「2TB 云盘」,
- 实际写的是「128GB 缓冲区」,
- 上传不及时、或缓冲区打满,就会灾难性溢出
希望 CloudDrive2 尽快优化缓冲区机制,现在肆意写缓冲区,实在是太吓人了。当然,也尽量不要一次传输大于缓冲区规模的数据,这样会比较安全。
That’s all.










